
The layout of your source code repositories will affect your company’s org chart, and if you get the first wrong, your ability to deliver software will suffer.
Conway’s Law states that your software architecture will naturally match your company’s org chart. I expand the law and believe that your source code repository structure will naturally influence your org structure, and if you are practicing “DevOps”, the wrong structure will result in chaos.
The code that defines the infrastructure of your service, commonly known as Infrastructure-as-Code, belongs in the same source code repository as the rest of your service.
Conway’s Law
Let’s quickly recap what Conway’s Law is all about. Melvin Conway summarized the law in his seminal paper as:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
Martin Fowler expands on the law with more detail:
Conway’s Law is essentially the observation that the architectures of software systems look remarkably similar to the organization of the development team that built it. It was originally described to me by saying that if a single team writes a compiler, it will be a one-pass compiler, but if the team is divided into two, then it will be a two-pass compiler.
Proving Conway’s Law is well outside the scope of this article, the Wikipedia article has a list of supporting evidence for anyone wishing to dig further. For today’s purposes we assume Conway’s Law is true.
Reactions to Conway’s Law
Martin Fowler explains three reactions to Conway’s Law, which matches what I’ve seen in practice.
The first reaction is to ignore it and assume the law doesn’t apply, which is much like ignoring gravity and then stepping off a cliff. A worse reaction than ignoring it is to fight against the law. I heard a senior leader once rant “We should fight Conway’s law!”. Instead of ignoring gravity you’re going to fight it and try to jump to leave earth’s orbit, with dysfunctional or even catastrophic consequences to your organization.

The second reaction is to accept the Law and ensure your org structure and architecture don’t clash. In Fowler’s words “recognize the impact of Conway’s Law, and ensure your architecture doesn’t clash with designers’ communication patterns.”
The third reaction is to use the Inverse Conway Maneuver. I really love this phrase. It was first coined by Johnny LeRoy and Matt Simons in this article in December 2010. Their thinking was that, paraphrasing Einstein, “you can’t fix a problem from within the same mindset that created it” and if your software system is dysfunctional, first fix the org chart, and then fix the system. That is, your org chart is what caused the dysfunction in the system architecture, so don’t lean on the same org chart to fix the architecture.

Taking the Inverse Conway Maneuver a step further when building a new system is to first plan the desired architecture of your system, and then change your org structure to match the desired architecture. That way you’re not fighting the law but using it to your advantage, and your new architecture will be implemented with little friction. That sounds fairly naive at first glance, and the realities of your teams needs to be taken into consideration. Martin Fowler again has a great quote:
I still remember one sharp technical leader, who was just made the architect of a large new project that consisted of six teams in different cities all over the world. “I made my first architectural decision” he told me. “There are going to be six major subsystems. I have no idea what they are going to be, but there are going to be six of them.”
In the early days at Arctic Wolf we talked frequently about Conway’s Law, and purposely kept a monorepo (single repository with all the source code in it), a monolith application (a single binary), and a flat organization for as long as we could, and probably a bit longer than we should have. But in the early days of a startup, when product market fit is still questionable and big changes come fast and frequently, having a simple architecture and organization allowed us to be very flexible and move very quickly.
DevOps
Before I can talk about source code, I need to briefly discuss DevOps. While I’ve lived DevOps practices well before it was named, I dislike the term because it’s nebulous, not well defined, frequently completely misunderstood, and has been taken over by marketing campaigns to the point of almost meaninglessness. That said, AWS’ definition is fairly succinct:
DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity…
The key is that DevOps is philosophies and practices. DevOps is not taking the old “Operations” team or “IT” team and re-labeling them as the “DevOps Team” and carrying on without any behavior change. Unfortunately many organizations do this, create a “DevOps Team”, and don’t understand why their velocity hasn’t increased, but exploring that is far outside the scope of this article.
The other way to describe a DevOps philosophy is to give a team the mandate “You build it, you run it” and give them the tools and responsibilities and guardrails to do that. The result is a team that can move quickly. I have written previously about my experience at Arctic Wolf where a DevOps philosophy led to hundreds of code deploys per day, and many other organizations have seen similar results.
Infrastructure As Code
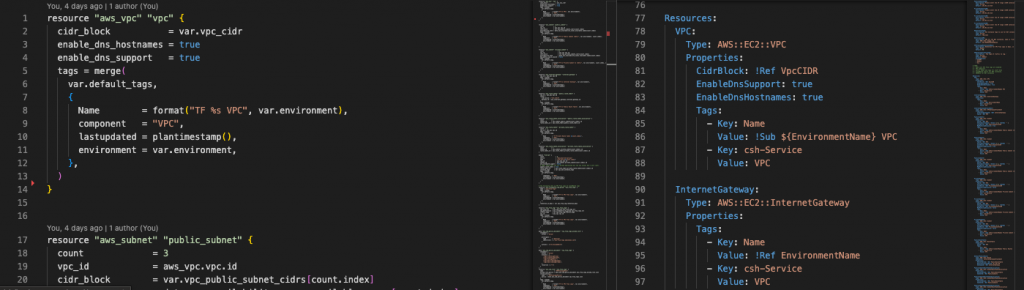
The code used to define the deployment of your service, commonly called Infrastructure-as-Code (IaC), belongs in the same source code repository as the rest of your application code. If the IaC is kept separately, because of Conway’s Law your org will end up with a separate Operations-type team maintaining the IaC, and you will lose the velocity a DevOps practice promises.
“Hold on!”, the confused reader might be thinking, “How did we start with Conway’s Law, take a detour into DevOps, and then make a sharp dive into Infrastructure-as-Code?” The three are related, bear with me.
A software development team practicing DevOps “you build it, you run it” is responsible for a few different aspects of the service’s lifecycle:
- Writing the application code that makes up the service
- Creating the automated tests, both unit and system/integration tests
- Developing the IaC that makes up the service in production
- Creating dashboards and alerts to observe the service.
In many organizations the first two are stored in one repo, the third in a separate repository frequently managed by a different team, and the fourth is a manual afterthought.
A quick side note, by IaC I mean everything that is needed to deploy the service to development, test environments, and production. That’s Docker files, Helm charts, Cloudformation or CDK, Terraform, shell scripts, CI/CD definitions, SQL scripts, etc.
Let’s dig into a few more definitive reasons why the application code, automated test code, and IaC belong in the same repo.
- IaC is code. It’s not anything special or strange or weird that belongs elsewhere. In my experience some developers seem to be fine with maintaining complex application code and strange test constructs (have you seen TDD frameworks?) but don’t want to touch IaC code like Terraform, leaving it for a DevOps team.
- The service is incomplete without the deployment definitions living alongside it. I’ll go as far as to say that the application code is mostly useless without the IaC, it can’t actually function as intended. If your service is hosted in Kubernetes on AWS and has, for example, a DynamoDB table – the application code by itself is useless without the Docker file to package it, the Helm chart to deploy it, and the CloudFormation or Terraform to define the DynamoDB table and the IAM artifacts required to grant permissions.
- It is far easier for a developer to reason about a service when all the code lives in one repo. It’s simpler to make changes to a complex service when the IaC lives in the same repo, especially when those changes span application and infrastructure code, like when changing a DynamoDB definition, or adding a new API call that requires an IAM policy change.
- Versioning is much simpler when all the artifacts live in one repo, especially when deploying continuously and from the main branch.
- The line between “application” or “service” code and IaC is increasingly becoming blurred. A traditional service from a decade ago might be a single binary that’s deployed by hand on VM’s or even physical hardware. A modern service could be a serverless application that cannot run outside of the cloud execution environment, with IAM roles giving permission to access AWS’s DynamoDB or Google’s BigTable, the structure of which is defined in IaC. The definition of the DynamoDB or BigTable is really no different from a SQL database definition which commonly lives beside the application code. Or the service could be made up of step functions where some of the application workflow is now defined in IaC. The blurring of those lines make it imperative to keep all the code in one repo.
The best reason to keep all the code in one repository is what happens if you don’t. Leaning on the Inverse Conway Maneuver, if you separate the application code from the IaC needed to deploy it, you will end up with a separate team owning the IaC, and be right back in the old world of having a separate Development and Operations teams, with all the dysfunction associated with that. Conway’s Law states that ending up with two teams is inevitable.
A brief tangent about my definition of “source code repository” – I’m really using that term as a proxy for a logical grouping of code, with a set of permissions wrapped around it. Typically this is implemented as a single GitHub or GitLab repository, but it might be, if you’re particularly unlucky, a subdirectory in something like Perforce.
What about shared services and the likes of a Platform Engineering group? There is definitely a need for IaC defining services like shared networking, shared Kubernetes clusters, security guardrails, etc, and that typically falls on the shoulders of specialist teams. As a company grows, splitting out a Platform Engineering and Security team is a natural evolution and keeping the IaC for shared services in separate repos is usually the right thing to do. As long as those teams don’t become the DevOps team, and those specialist teams can still treat their own source code in a DevOps fashion.
Conclusion
Keeping Conway’s Law top of mind when making architectural decisions, planning source code repository layouts, and making organizational changes is key to setting up your organization for success. Ignoring or fighting against Conway’s Law will result in a dysfunctional organization and architecture.